今天 Ferris 要大展身手了!
REPL(讀音:REH-ple)代表 Read-Eval-Print Loop,是一種互動式運算環境,也就是我們學習 Python 時在終端機輸入 python 會跳出來的東西:
REPL 允許開發人員輸入程式碼並立即看到結果,因此在資料工程的開發中非常有幫助,使用基於 REPL (IPython kernel) 構建的 Jupyter notebook 更是資料工作者的日常。
然而,Rust 是一門靜態編譯語言,而且強大的 LSP 讓我們在很多開發情境中根本用不上 REPL。
道理我都懂,但在處理資料的過程中,沒有用 REPL 看到結果並反覆實驗感覺還是卡卡的
我想應該不少人有相同的想法,所以 Google 還是開發了一個 Rust REPL evcxr,讓我們可以在終端機或 Jupiter notebook 中使用 (雖然名字有夠難記到根本意圖不讓人使用)。
在底層它會將我們的程式碼包進 main 函式,編譯那個檔案後,再把執行的輸出結果印出來。
所以今天我們會先介紹怎麼在 Rust 安裝 REPL,而且大放送一次介紹兩個,等等就知道理由了!
其實安裝的方法很簡單,得力於 Rust 強大的建構系統與套件管理工具 cargo,安裝 REPL 就是 one-liner:
cargo install evcxr_repl
安裝好後就能透過在終端機執行 evcxr 來開啟 REPL:
*怎麼還能打錯🤪
因為 evcxr 實在太難記了 (打這行就錯兩次),所以我推薦介面更好的另一個 REPL 專案 IRust,安裝也是很簡單:
cargo install irust
安裝好後就能透過在終端機執行 irust 來開啟 REPL,除了好打好記以外,可以看到介面也比較漂亮 (所以若要在終端機使用會比較推薦這個):
這兩個 REPL 都可以透過
ctrl+C或輸入:quit來離開,不用和用 Vim 時一樣成為 "永不放棄" 的使用者 😉:
上面提到的兩個專案也都有支援 Jupyter kernel,兩者的差別在於 IRust 還在開發中,因此如果要在 Jupyter 中使用的話,會比較推薦使用 evcxr。
這裡假設大家都已經有 Conda 跟 IPython 了,如果沒有的話,可以參考 Setup Anaconda, Jupyter, and Rust,這裡就不再贅述了。
安裝方法也是超不複雜,兩行就能搞定:
cargo install --locked evcxr_jupyter
evcxr_jupyter --install
IRust 則要透過 pip 來安裝,然後再透過 install 模組來建立 kernel:
python -m pip install irust_kernel
python -m irust_kernel.install
其實 IRsut 的安裝有個小插曲,在我跟著官方指令安裝時一直報錯,所以我只好先把專案叉下來除錯,還好作者很給力,幾小時就把 PR merge 進去了,所以現在就不用特別標明這個安裝方法有問題,真是可喜可賀~
如果安裝沒有問題的話,打開 Jupyter lab 就能看到兩個 kernel 囉: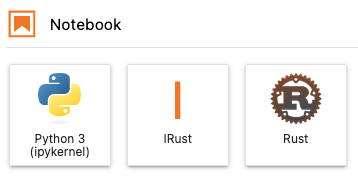
下圖為兩個 kernel 使用情況的比較: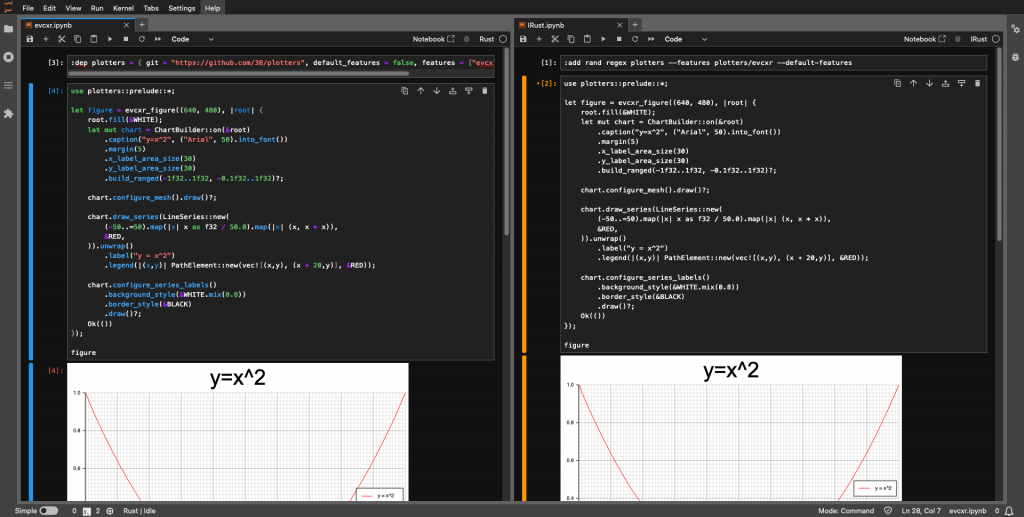
可以看到右邊的 IRust 並沒有支援語法突顯,而且目前使用上也發現不會它不會等待上一個 cell 執行完成,所以整體來說還是較推薦 evcxr kernel。
🚨 注意,由於 Rust 的 REPL 都還是會經過編譯的步驟,所以使用起來多少還是會比 Python 等直譯式語言需要多一點耐心,但在資料科學方面能有相同的開發體驗還是很讚的。
Rust 的安全性加上 "無懼並行" 的特色,使其格外適合用於資料工程之上,而且不需要擔心資料競爭 (Data Race)。
除了已經很棒的 Polars 和 DataFusion 以外,還有另一個不容小覷的小朋友 Rayon!
官方聲稱:
Rayon is a data-parallelism library for Rust.
It is extremely lightweight and makes it easy to convert a sequential computation into a parallel one.
It also guarantees data-race freedom.
看到關鍵字了嗎? EASY!簡單!
事實上,在大部分情況下我們要做的只有把原本的迭代器 .iter() 換成 .par_iter() 就好了:
既然現在 Jupyter notebook 也能跑 Rust 了,就來馬上實驗看看吧!
而要處理資料,第一步就是要有資料,這裡就以 Full TMDB Movies Dataset 2023 (930K Movies) 資料集來做示範,它是個 437.53 MB 的 CSV 檔,而我們的任務就定為簡單的三步驟就好:
, 換成 tab這裡使用的是 evcxr kernel,它引入外部 crate 的語法為 :dep <crate_name>。
第一個 cell 跟依然是熟悉的味道,引入相依函式庫:
:dep rayon
use std::fs::File;
use std::io;
use std::io::prelude::*;
use std::io::{BufReader, BufWriter};
use std::time::Instant;
use rayon::prelude::*;
然後我們需要幾個小幫手函式,首先是讀取 CSV:
fn read_csv(path: &str) -> Vec<String> {
let contents: io::Result<Vec<String>> =
BufReader::new(File::open(path).expect("Fail to open file!"))
.lines()
.collect();
return contents.expect("Something went wrong :( ");
}
再來是將逗號 , 換成 tab:
fn comma_2_tab(lines: Vec<String>) -> Vec<String> {
lines
.iter()
.map(|line: &String| -> String { line.replace(",", "\t") })
.collect::<Vec<String>>()
}
最後是輸出成 TSV:
fn to_csv(lines: Vec<String>) {
let mut writer: BufWriter<File> =
BufWriter::new(File::create("TMDB_movie_dataset_v11.tsv").expect("problem with file"));
writer
.write(lines.join("\n").as_bytes())
.expect("problem writing lines");
}
準備好就可以開始實驗了:
let before: Instant = Instant::now();
let lines: Vec<String> = read_csv("TMDB_movie_dataset_v11.csv");
let new_lines: Vec<String> = comma_2_tab(lines);
to_csv(new_lines);
println!("Elapsed time: {:.2?}", before.elapsed());
直接使用原生 Rust 完成整個任務耗時 1.64 秒 (BTW 原生 Python 約莫 1.7 秒,差別不大):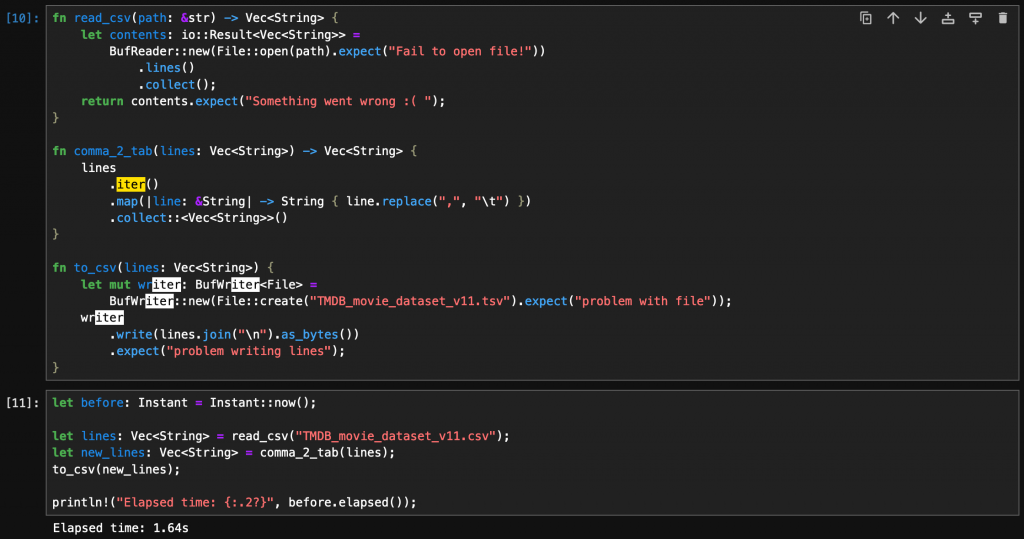
如果把 .iter() 換成 .par_iter() 則耗時 821.02 毫秒: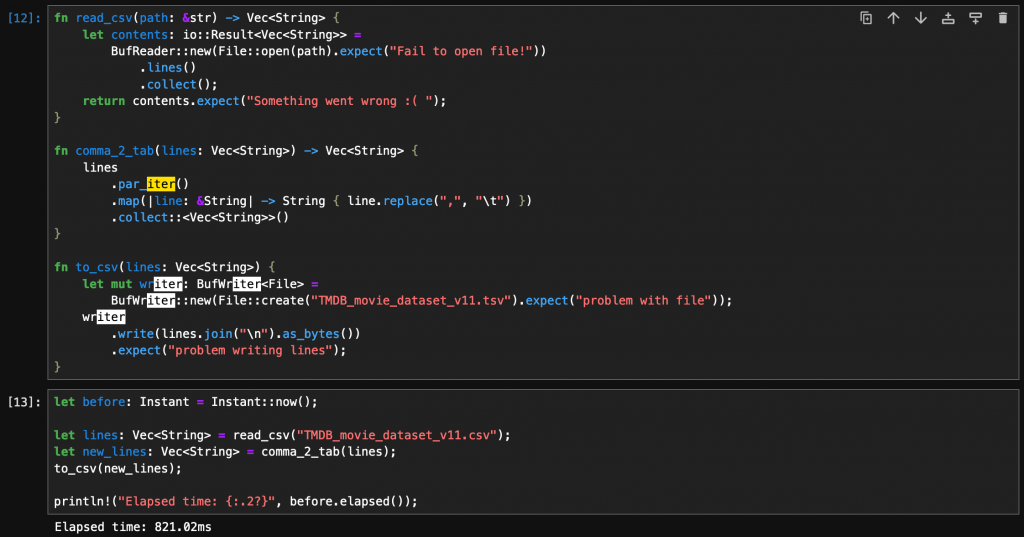
就這樣提升將近 50% 的表現!根本是搶來的哈哈哈 🤪
把最下面的程式碼放進
main函式就變成 Rust 腳本了。
而在執行 notebook 的 cell 時,其實可以在終端機看到熟悉的 Jupyter 執行訊息間夾雜著編譯狀況:
雖然這不是特別嚴謹的實驗,但也可以看出來 Rust 可以很輕鬆的對資料進行平行處理,未來的確是大有可期!
好啦,今天就到這,明天要進入各位孩子最愛的部分 — 模型開發囉,明天見啦~~~




 iThome鐵人賽
iThome鐵人賽